오늘은 정적 html 블로그의 게시물 url 싹 긁어오기
진짜 마지막 naver blog post url scrapping

파이썬 재귀함수로 블로그 paginate url 추출 if문 탈출구가 하이라이트
오늘은 정적 html 블로그에서 다음 url로 넘어가며블로그의 게시글 url들을 추출하는 작업을 계속반복하는 재귀함수를 파이썬으로 구현해보겠습니다. 실무로 배우는 파이썬 BeautifulSoup 모듈로
s-dobby.tistory.com
전 시간에 재귀까지 했으니 고비는 다 끝났구요.
추출한 모든 page에 접속해서 n개씩 있는
게시글 url들을 싹 긁어오면 끝입니다.
이전에 추출한 page url들 중 아무거나 하나
들어가봅시다, 아래 링크 걸어둘께요.
S-dobby의 Travel Log : 네이버 블로그
당신의 모든 기록을 담는 공간
blog.naver.com
들어가보면 제 블로그의 경우 한 페이지에
3개의 게시글이 있군요. 그리고 각 게시글
우상단에는 URL 복사라는 버튼이 있습니다.
당연 여기 게시글의 링크가 있겠죠?
F12 눌러 개발자도구를 열고 URL 복사 버튼에
마우스를 대고 우클릭, '검사'를 클릭하면
이렇게 html 해당하는 곳이 하이라이트되죠.
어디 있는 division이냐? 상위 div를 보니
class가 post2_post_function입니다.
(div 하위에 a 태그 많습니다. 기억!!)
그럼 이제 코드를 짜봅시다.
def stack_post(url, slist_post):
pf_div=prs_soup(url).find_all('div', {'class':'blog2_post_function'})
for i in pf_div:
for j in i.find_all('a'):
print(j) ; print(1) ; print(j.attrs) ; print(2)
if 'title' in j.attrs:
slist_post.append(j.attrs['title'])
slist_post=[] ; stack_post(nb_url, slist_post)
print(slist_post)
post(게시글)을 쌓을꺼니 stack_post라는 함수를
만들고 url을 parsing한 soup에서 아까 말한
클래스(URL복사)를 찾는데 게시글이 3개니
3개의 post_function div(pf_div)이 있겠죠?
find_all로 싹 긁어옵니다.

for문으로 pf_div 3개를 돌리고 그 안에서
링크(anchor, a)를 꺼내올껀데, 위에 div 잘 보라했죠.
그 하위에 a가 'url 복사'뿐이 아닙니다.
그러니 find_all로 a들을 찾아 또 한번 for문 돌리기
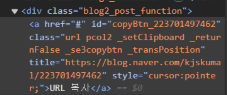

아까 div 하위 a 태그 게시글 url이 있는 곳을 보면
url이 title안에 있습니다. a 테그 긁어 온 것을
.attrs해주면 속성 데이터(Meta-data)를 dictionary
형태로 바꿔주니 여기서 title이란 key로 value를
긁어오면 url이 scrap 되겠죠. 이 url들을
slist_post 안에 append로 붙여줍니다.
** attributes : 속성.. similar with
** meta : ~의 너머에, 초월하여(그리스어 유래)

블로그 카테고리 전체보기 페이지
paginate 1에 대해 stack_post 돌려보면
위와 같이 3개의 url이 추출 잘 되네요~
이제, 이걸 합쳐서 최종본으로 만들면
끝입니다. 진짜 끝~~
import requests ; from bs4 import BeautifulSoup as bsp
nb="https://blog.naver.com" ; id='kjskumal'
def prs_soup(url): # parsing ## raise for status: HTTP 오류 시 예외 처리
rsp=requests.get(url) ; rsp.raise_for_status() ; html_ctt=rsp.text
return bsp(html_ctt, 'html.parser') # bsp 사용해 HTML 파싱
def get_pg(soup): # paginate ## <div>에서 <a> 부분 가져오기
pgn_div=soup.find('div', {'class':'blog2_paginate'})
return [nb+pg.get('href') for pg in pgn_div.find_all('a')]
def rc_pgn(url, slist_pgn): # recursion(재귀) # sum_list
list_pg=get_pg(prs_soup(url))
slist_pg.extend(i for i in list_pg if i not in slist_pg)
np=list_pg[-1] ; cp=slist_pg[-1] # next_page, current page
if np[np.find('=',-5)+1:]<cp[cp.find('=',-5)+1:]:
return slist_pg # 재귀 종료 스위치
rc_pgn(np, slist_pg)
def stack_post(url, slist_post):
pf_div=prs_soup(url).find_all('div', {'class':'blog2_post_function'})
for i in pf_div:
for j in i.find_all('a'):
if 'title' in j.attrs:
slist_post.append(j.attrs['title'])
nb_url=f'{nb}/PostList.naver?blogId={id}&categoryNo=0&from=postList'
slist_pg=[] ; rc_pgn(nb_url, slist_pg) # slist_pg에 scrap 완료
stack_post(nb_url, slist_pg)
slist_post=[] ; stack_post(nb_url, slist_post)
for i in slist_pg:
stack_post(i, slist_post)
for i in slist_post:
print(i.replace('blog','m.blog'))
위 코드를 id만 수정해서 돌리면
블로그 게시글 모든 url들이 추출되어 print됩니다.
nb_url(페이지1)에 대해 stack_post하고
rc_pgn으로 재귀 돌린 페이지들의 리스트
slist_pg에는 페이지2부터 끝까지 있으니
for문으로 모든 페이지에 대해 stack_post
마지막으로, 모바일 url로 바꿔야해서
m.blog 주소로 바꾸는 replace를
전체 for문으로 바꿔 주었습니다.

위와 같이 게시글 url 전부 잘 추출되는걸
확인할 수 있네요.
정적 html 블로그 게시글 url all scrapping
끝~~~
'실무로 배우는 파이썬 > prj1. 블로그html 게시글 url 추출' 카테고리의 다른 글
| 게시글url scrap 파이썬 tqdm으로 크롤링 진행도 게이지바 표시 crawling process gauge bar visualization (0) | 2025.02.05 |
|---|---|
| 파이썬 재귀함수로 블로그 paginate url 추출 if문 탈출구가 하이라이트 (0) | 2025.01.25 |
| 실무로 배우는 파이썬 BeautifulSoup 모듈로 파싱한 블로그 html의 paginate anchor 링크들 리스트로 출력하기 (5) | 2025.01.23 |
| 네이버블로그 모든 게시글 url 추출해 사이트맵 만들기 정적,동적 html 확인 방법 (1) | 2025.01.20 |